
Woboq Code Browser: under the hood
A few years ago, I was introducing the code browser and code.woboq.org
Since the then, we implemented a few new features and made the source code available, which you can browse from the code browser itself.
In this article, I give more technical information on how this is all done.
What/Why a code browser?
As a developer, I spend more time reading code than writing, and I found reading code online a rather poor experience. Hence, I made a way to publish code in a way that can be read just like in a good IDE, with links, tooltips, and semantic highlighting. Read more about it in the original blog post.
Architecture Overview
The idea is that there is a generator that generates all the .html pages ahead of time. This is a bit like a compilation. In the process we also fill up a database containing all the symbols and where they are defined or used, as well as other information such as the documentation.
The database
Because NoSQL is trendy, we use a well-known NoSQL database directly included in the kernel: the file system ☺. There is a huge directory containing one file per global symbol. Each file contains all the information you see in the tooltip. The type of the variable, the list of its uses and its documentation. The HTML files has tags referencing the symbol, the JavaScript can then do an AJAX request on that file in order to render the tooltip contents.
For example, the file for QQmlEngine::removeImageProvider
, looks like this:
<dec f='qtdeclarative/src/qml/qml/qqmlengine.h' l='132' type='void QQmlEngine::removeImageProvider(const QString & id)'/> <def f='qtdeclarative/src/qml/qml/qqmlengine.cpp' l='1209' type='void QQmlEngine::removeImageProvider(const QString & providerId)'/> <doc f='qtdeclarative/src/qml/qml/qqmlengine.cpp' l='1204'>/*! Removes the image provider for \a providerId. \sa addImageProvider(), QQuickImageProvider */</doc> <use f='qtdeclarative/tests/auto/quick/qquickimageprovider/tst_qquickimageprovider.cpp' l='360' u='c' c='_ZN23tst_qquickimageprovider14removeProviderEv'/> <use f='qtdeclarative/tests/auto/quick/qquickimageprovider/tst_qquickimageprovider.cpp' l='389' u='c' c='_ZN23tst_qquickimageprovider15imageProviderIdEv'/>
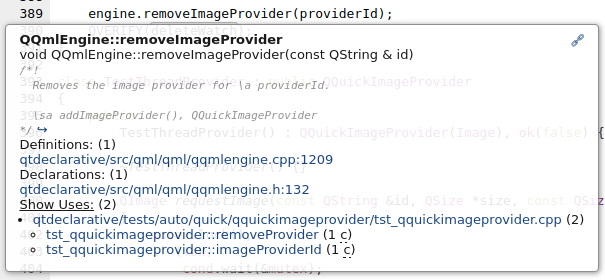
You can see that there is one entry for the declaration, the definition, the documentation, and one for each usage.
This is the information displayed in the tooltip.
We also store information about inherited classes or methods.
See the symbol page that shows information from the tooltip and more.
This way, the whole generated browsable code is just a set of files that can be served by any simple web server. The whole thing is maybe three times as big as the original source code. Which still amounts to several GB when we host so much source code. However, it is highly compressible. To save space and ease upload, we use squashfs images. That way we even have atomic updates ☺
Using Clang to parse C/C++
Here is the interesting part: how is the generator working?
Clang is more than just a compiler, it is really a library to parse C and C++.
Clang provides all the tools required, all I have to do is to create an clang::ASTConsumer.
Once the parser has finished its job, we can then visit the full AST of the translation unit with the clang::RecursiveASTVisitor.
As explained in this tutorial.
We then visit all the declarations and usage nodes. We know the source location of the node,
so we know if we are in a file that we should generate. In particular, we do not generate header files twice, so if
the header file has already been parsed, we ignore that node.
Knowing the location of the node, we can register a HTML tag for it. We give a data-ref
tag with the mangled name of the symbol so the
JavaScript will be able to show the tooltip, and we give proper classes so it can be semantically styled.
We also register the use in the database.
Macro Expansions
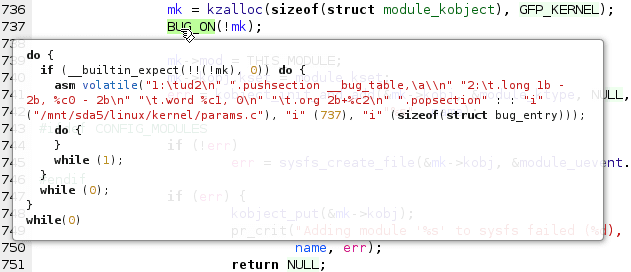
We also show the expansion of a macro in the macro tooltip.
Macros does not appear as node in the AST because they are expanded before,
in the pre-processing phase.
We use clang::PPCallback to be notified each time a macro is expended.
Unfortunately, getting the actual expansion is far from easy since the expansion never appears as
such in memory. What happens is that the pre-processor just provides tokens to the parser.
We have to
pre-process again the macro and write the token strings in to tooltip.
Documentation Comments
Comments are ignored by the parser so they are not part of the AST.
We do another pass in which, for each file, in which we find comments and keywords for the
basic syntax coloration of things that are not in the AST, and color these element
appropriately. We will try to associate the comments with
the closest declaration or definition, so it can go in the database (in the tooltip).
We also recognize some doxygen commands such as \fn which associate the
comment with a different declaration.
Qt SIGNAL and SLOT
We detect a few Qt extensions. We recognize calls to QObject::connect, QMetaObject::activate and
similar call like QTimer::singleShot (See the full list of recognized functions). Since SIGNAL and SLOT
are macros that transform their argument to string, we can easily extract the string literal and parse that in order to
find to what method it is. We know in which class to look because know the type of the QObject sub class of the receiver parameter.
Usage classification
When looking at the AST, we see how the variables are used. We can classify if the variable was simply read, or modified. We add a little letter in the uses in the tooltip. If you click on the little 🔗 icon in the top-right of the tooltip you can filter by type of usage.

Similarly, we see when arguments are passed by references, and we annotate the source code with little &. We also annotate the code with little ⎀
when there is an implicit call to a constructor or conversion operator.
Clang Tooling
The clang tooling needs to interface with the build system to know the list of compilation commands. (The flags passed to the compiler
such as the include paths, the defines, or other languages options).
All the commands are in a compilation database hold in a compile_commands.json file. If one use cmake as a build system, it is
trivial to generate this list of command by passing -DCMAKE_EXPORT_COMPILE_COMMANDS=ON. Ninja also can export the compile_commands.
But with others build system it is a bit more complicated. With some build system such as qmake, we parse the output of make -n.
When that is not supported, there is a script used as a proxy compiler that records the compilation commands.
Find out more about this in the README.
Javascript Code
Once the static HTML and the database have been generated, the rest of the logic happens client side. The server is simply serving static files. The Javascript code runs in the browser will fetch these files and enable all the features such as the tooltip or the search.
Search for a file or function
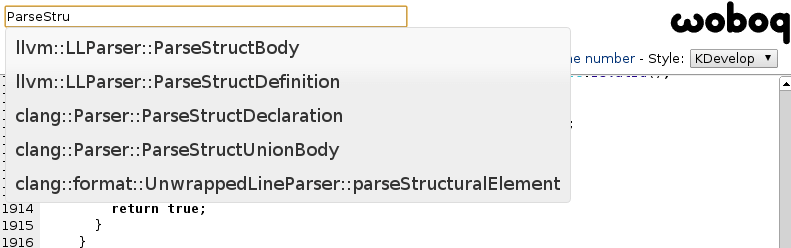
In order to find a file, the browser will first download, via AJAX, a file containing the
list of all the files for this project. For the functions, a file containing all the functions
would be too big. We therefore split the functions in several files starting with the
first two letters of the function. So when someone starts typing "Parse", the file
fnSearch/pa (pa being the first two letters) gets downloaded to find matches in there.
Conclusion
This was explaining how code.woboq.org works. Get it for your own code!
Woboq is a software company that specializes in development and consulting around Qt and C++. Hire us!
If you like this blog and want to read similar articles, consider subscribing via our RSS feed (Via Google Feedburner, Privacy Policy), by e-mail (Via Google Feedburner, Privacy Policy) or follow us on twitter or add us on G+.
![]()
![]()
![]()
![]()
![]()
Article posted by Olivier Goffart on 24 October 2016
Click to subscribe via RSS or e-mail on Google Feedburner. (external service).
Click for the privacy policy of Google Feedburner.
Google Analytics Tracking Opt-Out
Loading comments embeds an external widget from disqus.com.
Check disqus privacy policy for more information.