
Introduction to Lock-free Programming with C++ and Qt
This blog post is an introduction to lock-free programming. I'm writing this because this is the pre-requisite to understand my next post. This was also the content of my presentation for Qt Developer Days 2011.
Lock-free programming is the design of algorithms and data structures that do not acquire locks or mutexes.
When different threads in your program need to access the same data, we must ensure that the data is always in a coherent state when used. One way to achieve that is to do locking. A thread will acquire a mutex to write the data. That thread may touch the data structure and have it in an inconsistent state as it holds the mutex, but this is not a problem because other threads cannot access the data at this time as they will block waiting for the mutex to be released. While a thread is waiting, the OS will schedule another thread or process or let the CPU core rest.
What is wrong with Mutexes?
Mutexes are perfectly fine. But you have a problem if there is lock contention. If you want your algorithm to be fast, you want to use the available cores as much as possible instead of letting them sleep. A thread can hold a mutex and be de-scheduled by the CPU (because of a cache miss or its time slice is over). Then all the threads that want to acquire this mutex will be blocked. And if you have a lot of blocking, the OS also needs to do more context switches which are expensive because they clear the caches.
Other problems may arise if you do real time programming (priority inversion, convoying, ...). Mutexes also cannot be used in signal handlers.
Another example: Let us suppose you want to split your program into different processes so the whole application does not crash if one process crashes. (This is what modern browsers are doing by having the rendering of the page in a different process.) But if the process crashes while holding a shared lock you are in big trouble as this will most likely cause a dead lock in the main application.
So how can we do it without locking?
Modern CPUs have something called atomic operations. There are libraries that have APIs that let you use those atomic operations. Qt has two classes: QAtomicInt and QAtomicPointer. Other libraries or languages might have different primitives, but the principles are the same.
QAtomic API
I won't go into the detail of the API here as you can read the documentation of QAtomicInt and QAtomicPointer
But here are the highlights: Both classes have a similar API. They wrap an int or a pointer and allow to make atomic operations on it. There are 3 main operations: fetchAndAdd, fetchAndStore, and testAndSet. They are available in 4 variants, one for each ordering.
The one used here is testAndSet.
It is also called Compare and Swap
in the literature.
Here is a non-atomic implementation
bool QAtomicInt::testAndSet(int expectedValue, int newValue) {
if (m_value != expectedValue)
return false;
m_value = newValue;
return true;
}
What it does: it changes the wrapped value only if the value is the expected value, else it does not touch it and returns false.
It is atomic, meaning that if two threads operate at the value on the same time it stays consistent.
Of course, it is not implemented like this as it would not be atomic. It is implemented using assembly instructions. Qt's atomic classes are one of the very few places inside Qt implemented with assembly on each platform.
Memory Ordering
Today's CPUs have what is called out of order execution. What it means is that at each clock cycle, the CPU might read several instructions (say 6) from the memory and decode them and store them in a pool of instructions. The wires in the CPU will compute the dependencies between the instructions and feed the processing units with the instructions in the best possible order making the most efficient use of the CPU. So the instructions, and especially the reads and the store, are executed in an order that might be different from the one in the original program. The CPU is allowed to do that as long as it gives the same result on that thread.
However, we want to make sure that the ordering is preserved when we play with atomic operations. Indeed, if the memory is written in a different order, the data structure may be in an inconsistent state when other threads read the memory.
Here is an example:
QAtomicPointer<int> p; int x; //... x = 4; p.fetchAndStoreRelease(&x);
It is important that when p is set to &x, the value of x is already 4. Else another thread could see the value of p that is still pointing to something else.
This is done by adding the proper memory fence in the program. Memory fences are special instructions that tell the CPU to not reorder. We have 4 kind of fences:
- Acquire
- No reads or writes that happen after will be moved before the atomic operations.
- Release
- The opposite of Acquire: No reads or writes are going to be moved after.
- Ordered
- It is a mix of the two previous orderings: Nothing can be moved after or before. This is the safest and the one to use if you don't know which one to use.
- Relaxed
- No memory fences are added.
The fence hints are added to the functions because on some architectures, there is one assembly instruction to do the atomic operation and the fence.
The fences are only there for keeping the CPU away from reordering. It has nothing to do with the fact that the compiler might also re-order everything. We make sure the compiler does not re-order by having 'volatile' access.
Lock-free Stack
We will here design a stack that works without locking:
class Stack {
QAtomicPointer<Node> head;
public:
Stack() : head(0) {}
void push(Node *n) {
do {
n->next = head;
} while(!head.testAndSetOrdered(n->next, n));
}
Node *pop() {
Node *n;
do {
n = head;
if (!n)
return 0;
} while(!head.testAndSetOrdered(n, n->next));
return n;
}
};
I'll use drawings to show how the code works:
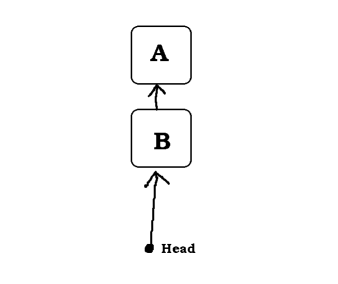
It is basically implemented as a linked list: each node has a pointer to the next node, and we have a pointer to the first node called head.
Push
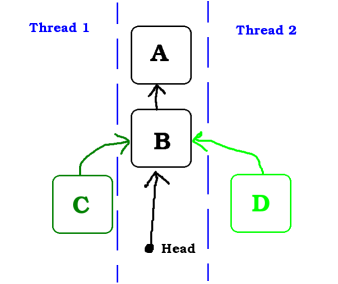
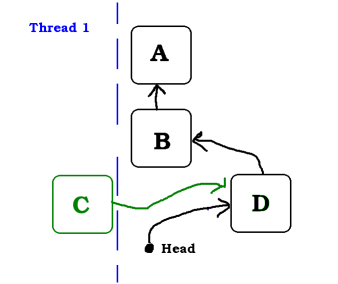
In this example, two threads want to push a node to the stack.
Both threads have already executed the line n->next = head and will soon execute
the atomic operation that will change head from the former head (B)
to n (C or D)
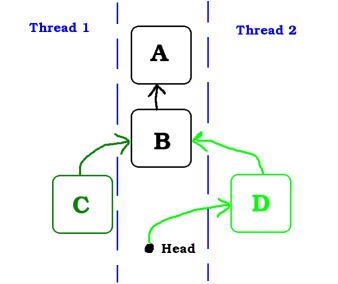
In this image we see that the Thread 2 was first. And D is now on the stack.
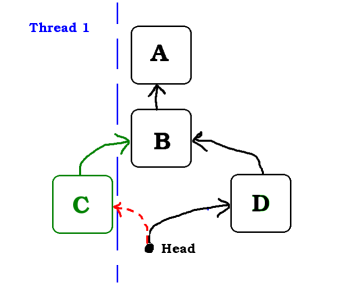
The testAndSet in Thread 1 will fail. The head is not B anymore. head is not changed, meaning that the node D is still on the stack.
The Thread 1 will be notified that the testAndSet has failed and will then retry with the new head which is now D
Benchmark
So you can try yourself with this little example:
lockfreestack.cpp
(Download the file in a new directory and do qmake -project && qmake && make)
This program first pushes 2 million nodes to the list using 4 threads, measuring the time it takes. Once all the threads have finished pushing, it will pop all those nodes using 4 threads and measure how long that takes
The program contains a version of the stack that uses QMutex (in the #if 0 block)
Results: (on my 4 core machine)
| Push (ms) | Pop (ms) | Total (real / user / sys) (ms) | |
|---|---|---|---|
| With QMutex | 3592 | 3570 | 7287 / 4180 / 11649 |
| Lock-free | 185 | 237 | 420 / 547 / 297 |
Not bad: the lock-free stack is more than 100 times faster. As you can see, there is much less contention (the real is smaller than the user) in the lock-free case, while with the mutex, a lot of time is spent blocking.
The ABA problem
OK, there is actually a big bug in our implementation. It works well in the benchmark because we push all the node then pop them all. There is no thread that pushes an pops nodes at the same time. In a real application, we might want to have a stack that works even if threads are pushing and popping nodes at the same time.
But what is the problem exactly? Again, I'll use some images to show:
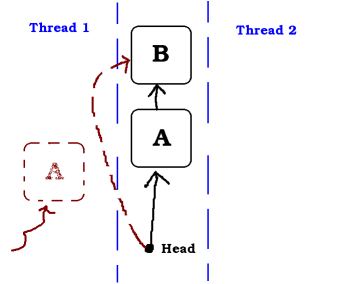
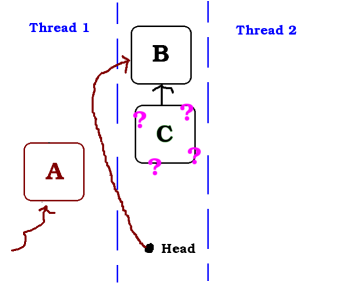
In this example, the Thread 1 wants to pop a node. It take the address of A and will do a testAndSet to change head atomically from A to B. But it is de-scheduled by the OS just before the atomic operation while another thread is being executed
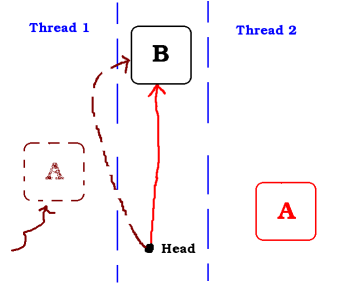
While Thread 1 is sleeping, Thread 2 also pops a node, so A is not on the stack anymore.
If Thread 1 wakes up now, the atomic operation in Thread 1 will fail because head is not anymore equal to A. But Thread 1 does not wake up and Thread 2 continues...
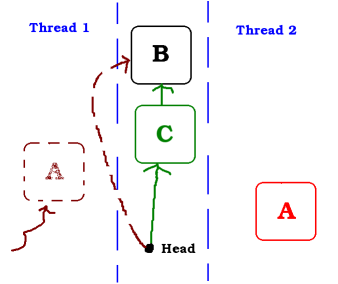
Thread 2 has pushed a node (C). Again, if thread 1 would wake up now, there would not be any problem, but it still does not wake up.
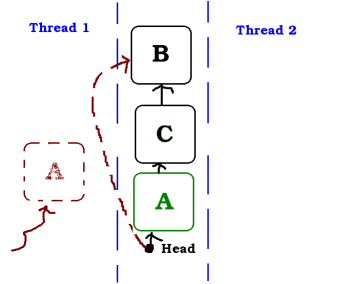
And Thread 2 pushes A back in the stack
But now, Thread 1 wakes up and execute the testAndSet, which succeeds as head is A again. This is a problem because now C is leaking.
It could have been even worse if Thread 2 had popped the node B.
Solutions to the ABA Problem
Every problem has solutions. It is outside the scope of this article to show the solutions in details. I would just give some hint that will orient your research on the web:
- Adding a serial number to the pointer, incremented each time a node is popped. It can be stored inside the least significant bits of the pointer (considering it points to an aligned address). But that might not be enough bits. Instead of using pointers, one can use indexes in array, leaving more bits for the serial number.
- Hazard pointer: Each thread puts the pointer it reads in a list readable by all threads. Those lists are then checked before reusing a node.
- Double or multiple word compare and swap. (which is possible using single word compare and swap)
Conclusions
As you might see, developing lock-free algorithm requires much more thinking than writing blocking algorithms. So keep mutexes, unless you have a lot of lock contention or are looking for a challenge.
A question I often got is whether it is not better to lock in order to let the other threads working instead of entering what might appear to be a spin lock. But the reality is that it is not a spin lock. The atomic operations succeed much more often than they fail. And they only fail if there was progress (that is, another thread made progress).
If you need help in your Qt applications regarding threads and locking, maybe Woboq can help you.
Woboq is a software company that specializes in development and consulting around Qt and C++. Hire us!
If you like this blog and want to read similar articles, consider subscribing via our RSS feed (Via Google Feedburner, Privacy Policy), by e-mail (Via Google Feedburner, Privacy Policy) or follow us on twitter or add us on G+.
![]()
![]()
![]()
![]()
![]()
Article posted by Olivier Goffart on 13 December 2011
Click to subscribe via RSS or e-mail on Google Feedburner. (external service).
Click for the privacy policy of Google Feedburner.
Google Analytics Tracking Opt-Out
Loading comments embeds an external widget from disqus.com.
Check disqus privacy policy for more information.